|
|
@@ -19,7 +19,7 @@ Gijs van der Voort\\
|
|
|
Richard Torenvliet\\
|
|
|
Jayke Meijer\\
|
|
|
Tadde\"us Kroes\\
|
|
|
-Fabi\'en Tesselaar
|
|
|
+Fabi\"en Tesselaar
|
|
|
|
|
|
\tableofcontents
|
|
|
\pagebreak
|
|
|
@@ -71,25 +71,6 @@ defining what problems we have and how we want to solve these.
|
|
|
\subsection{Extracting a letter and resizing it}
|
|
|
|
|
|
Rewrite this section once we have implemented this properly.
|
|
|
-%NO LONGER VALID!
|
|
|
-%Because we are already given the locations of the characters, we only need to
|
|
|
-%transform those locations using the same perspective transformation used to
|
|
|
-%create a front facing license plate. The next step is to transform the
|
|
|
-%characters to a normalized manner. The size of the letter W is used as a
|
|
|
-%standard to normalize the width of all the characters, because W is the widest
|
|
|
-%character of the alphabet. We plan to also normalize the height of characters,
|
|
|
-%the best manner for this is still to be determined.
|
|
|
-
|
|
|
-%\begin{enumerate}
|
|
|
-% \item Crop the image in such a way that the character precisely fits the
|
|
|
-% image.
|
|
|
-% \item Scale the image to a standard height.
|
|
|
-% \item Extend the image on either the left or right side to a certain width.
|
|
|
-%\end{enumerate}
|
|
|
-
|
|
|
-%The resulting image will always have the same size, the character contained
|
|
|
-%will always be of the same height, and the character will always be positioned
|
|
|
-%at either the left of right side of the image.
|
|
|
|
|
|
\subsection{Transformation}
|
|
|
|
|
|
@@ -128,7 +109,7 @@ registered. For explanation purposes let the square be 3 x 3. \\
|
|
|
value of the pixel around the middle pixel is evaluated. If it's value is
|
|
|
greater than the threshold it will be become a one else a zero.
|
|
|
|
|
|
-\begin{figure}[h!]
|
|
|
+\begin{figure}[H]
|
|
|
\center
|
|
|
\includegraphics[scale=0.5]{lbp.png}
|
|
|
\caption{LBP 3 x 3 (Pietik\"ainen, Hadid, Zhao \& Ahonen (2011))}
|
|
|
@@ -163,7 +144,7 @@ order. Starting with dividing the pattern in to cells of size 16.
|
|
|
|
|
|
\item Compute a histogram for each cell.
|
|
|
|
|
|
-\begin{figure}[h!]
|
|
|
+\begin{figure}[H]
|
|
|
\center
|
|
|
\includegraphics[scale=0.7]{cells.png}
|
|
|
\caption{Divide in cells(Pietik\"ainen et all (2011))}
|
|
|
@@ -224,9 +205,10 @@ reader will only get results from this version.
|
|
|
Now we are only interested in the individual characters so we can skip the
|
|
|
location of the entire license plate. Each character has
|
|
|
a single character value, indicating what someone thought what the letter or
|
|
|
-digit was and four coordinates to create a bounding box. If less then four points have been set the character will not be saved. Else, to make things not to
|
|
|
-complicated, a Character class is used. It acts as an associative list, but it gives some extra freedom when using the
|
|
|
-data.
|
|
|
+digit was and four coordinates to create a bounding box. If less then four
|
|
|
+points have been set the character will not be saved. Else, to make things not
|
|
|
+to complicated, a Character class is used. It acts as an associative list, but
|
|
|
+it gives some extra freedom when using the data.
|
|
|
|
|
|
When four points have been gathered the data from the actual image is being
|
|
|
requested. For each corner a small margin is added (around 3 pixels) so that no
|
|
|
@@ -283,6 +265,10 @@ tried the following neighbourhoods:
|
|
|
\caption{Tested neighbourhoods}
|
|
|
\end{figure}
|
|
|
|
|
|
+We name these neighbourhoods respectively (8,3)-, (8,5)- and
|
|
|
+(12,5)-neighbourhoods, after the number of points we use and the diameter
|
|
|
+of the `circle´ on which these points lay.\\
|
|
|
+\\
|
|
|
We chose these neighbourhoods to prevent having to use interpolation, which
|
|
|
would add a computational step, thus making the code execute slower. In the
|
|
|
next section we will describe what the best neighbourhood was.
|
|
|
@@ -315,12 +301,47 @@ increasing our performance, so we only have one histogram to feed to the SVM.
|
|
|
|
|
|
For the classification, we use a standard Python Support Vector Machine,
|
|
|
\texttt{libsvm}. This is a often used SVM, and should allow us to simply feed
|
|
|
-the data from the LBP and Feature Vector steps into the SVM and receive results.\\
|
|
|
+the data from the LBP and Feature Vector steps into the SVM and receive
|
|
|
+results.\\
|
|
|
\\
|
|
|
Using a SVM has two steps. First you have to train the SVM, and then you can
|
|
|
use it to classify data. The training step takes a lot of time, so luckily
|
|
|
\texttt{libsvm} offers us an opportunity to save a trained SVM. This means,
|
|
|
-you do not have to train the SVM every time.
|
|
|
+you do not have to train the SVM every time.\\
|
|
|
+\\
|
|
|
+We have decided to only include a character in the system if the SVM can be
|
|
|
+trained with at least 70 examples. This is done automatically, by splitting
|
|
|
+the data set in a trainingset and a testset, where the first 70 examples of
|
|
|
+a character are added to the trainingset, and all the following examples are
|
|
|
+added to the testset. Therefore, if there are not enough examples, all
|
|
|
+available examples end up in the trainingset, and non of these characters
|
|
|
+end up in the testset, thus they do not decrease our score. However, if this
|
|
|
+character later does get offered to the system, the training is as good as
|
|
|
+possible, since it is trained with all available characters.
|
|
|
+
|
|
|
+\subsection{Supporting Scripts}
|
|
|
+
|
|
|
+In order to work with the code, we wrote a number of scripts. Each of these
|
|
|
+scripts is named here and a description is given on what the script does.
|
|
|
+
|
|
|
+\subsection*{\texttt{find\_svm\_params.py}}
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+\subsection*{\texttt{LearningSetGenerator.py}}
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+\subsection*{\texttt{load\_characters.py}}
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+\subsection*{\texttt{load\_learning\_set.py}}
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+\subsection*{\texttt{run\_classifier.py}}
|
|
|
+
|
|
|
|
|
|
\section{Finding parameters}
|
|
|
|
|
|
@@ -348,7 +369,14 @@ value, and what value we decided on.
|
|
|
|
|
|
The first parameter to decide on, is the $\sigma$ used in the Gaussian blur. To
|
|
|
find this parameter, we tested a few values, by trying them and checking the
|
|
|
-results. It turned out that the best value was $\sigma = 1.4$.
|
|
|
+results. It turned out that the best value was $\sigma = 1.4$.\\
|
|
|
+\\
|
|
|
+Theoretically, this can be explained as follows. The filter has width of
|
|
|
+$6 * \sigma = 6 * 1.4 = 8.4$ pixels. The width of a `stroke' in a character is,
|
|
|
+after our resize operations, around 8 pixels. This means, our filter `matches'
|
|
|
+the smallest detail size we want to be able to see, so everything that is
|
|
|
+smaller is properly suppressed, yet it retains the details we do want to keep,
|
|
|
+being everything that is part of the character.
|
|
|
|
|
|
\subsection{Parameter \emph{cell size}}
|
|
|
|
|
|
@@ -377,7 +405,7 @@ are not significant enough to allow for reliable classification.
|
|
|
The neighbourhood to use can only be determined through testing. We did a test
|
|
|
with each of these neighbourhoods, and we found that the best results were
|
|
|
reached with the following neighbourhood, which we will call the
|
|
|
-(12, 5)-neighbourhood, since it has 12 points in a area with a diameter of 5.
|
|
|
+(12,5)-neighbourhood, since it has 12 points in a area with a diameter of 5.
|
|
|
|
|
|
\begin{figure}[H]
|
|
|
\center
|
|
|
@@ -445,27 +473,6 @@ $\gamma = 0.125$.
|
|
|
The goal was to find out two things with this research: The speed of the
|
|
|
classification and the accuracy. In this section we will show our findings.
|
|
|
|
|
|
-\subsection{Speed}
|
|
|
-
|
|
|
-Recognizing license plates is something that has to be done fast, since there
|
|
|
-can be a lot of cars passing a camera in a short time, especially on a highway.
|
|
|
-Therefore, we measured how well our program performed in terms of speed. We
|
|
|
-measure the time used to classify a license plate, not the training of the
|
|
|
-dataset, since that can be done offline, and speed is not a primary necessity
|
|
|
-there.\\
|
|
|
-\\
|
|
|
-The speed of a classification turned out to be reasonably good. We time between
|
|
|
-the moment a character has been 'cut out' of the image, so we have a exact
|
|
|
-image of a character, to the moment where the SVM tells us what character it is.
|
|
|
-This time is on average $65$ ms. That means that this
|
|
|
-technique (tested on an AMD Phenom II X4 955 Quad core CPU running at 3.2 GHz)
|
|
|
-can identify 15 characters per second.\\
|
|
|
-\\
|
|
|
-This is not spectacular considering the amount of calculating power this cpu
|
|
|
-can offer, but it is still fairly reasonable. Of course, this program is
|
|
|
-written in Python, and is therefore not nearly as optimized as would be
|
|
|
-possible when written in a low-level language.
|
|
|
-
|
|
|
\subsection{Accuracy}
|
|
|
|
|
|
Of course, it is vital that the recognition of a license plate is correct,
|
|
|
@@ -488,6 +495,35 @@ grid-searches, finding more exact values for $c$ and $\gamma$, more tests
|
|
|
for finding $\sigma$ and more experiments on the size and shape of the
|
|
|
neighbourhoods.
|
|
|
|
|
|
+\subsection{Speed}
|
|
|
+
|
|
|
+Recognizing license plates is something that has to be done fast, since there
|
|
|
+can be a lot of cars passing a camera in a short time, especially on a highway.
|
|
|
+Therefore, we measured how well our program performed in terms of speed. We
|
|
|
+measure the time used to classify a license plate, not the training of the
|
|
|
+dataset, since that can be done offline, and speed is not a primary necessity
|
|
|
+there.\\
|
|
|
+\\
|
|
|
+The speed of a classification turned out to be reasonably good. We time between
|
|
|
+the moment a character has been 'cut out' of the image, so we have a exact
|
|
|
+image of a character, to the moment where the SVM tells us what character it
|
|
|
+is. This time is on average $65$ ms. That means that this
|
|
|
+technique (tested on an AMD Phenom II X4 955 CPU running at 3.2 GHz)
|
|
|
+can identify 15 characters per second.\\
|
|
|
+\\
|
|
|
+This is not spectacular considering the amount of calculating power this CPU
|
|
|
+can offer, but it is still fairly reasonable. Of course, this program is
|
|
|
+written in Python, and is therefore not nearly as optimized as would be
|
|
|
+possible when written in a low-level language.\\
|
|
|
+\\
|
|
|
+Another performance gain is by using one of the other two neighbourhoods.
|
|
|
+Since these have 8 points instead of 12 points, this increases performance
|
|
|
+drastically, but at the cost of accuracy. With the (8,5)-neighbourhood
|
|
|
+we only need 1.6 ms seconds to identify a character. However, the accuracy
|
|
|
+drops to $89\%$. When using the (8,3)-neighbourhood, the speedwise performance
|
|
|
+remains the same, but accuracy drops even further, so that neighbourhood
|
|
|
+is not advisable to use.
|
|
|
+
|
|
|
\section{Conclusion}
|
|
|
|
|
|
In the end it turns out that using Local Binary Patterns is a promising
|
|
|
@@ -543,14 +579,17 @@ every team member was up-to-date and could start figuring out which part of the
|
|
|
implementation was most suited to be done by one individually or in a pair.
|
|
|
|
|
|
\subsubsection*{Who did what}
|
|
|
-Gijs created the basic classes we could use and helped the rest everyone by
|
|
|
-keeping track of what required to be finished and whom was working on what.
|
|
|
+Gijs created the basic classes we could use and helped everyone by keeping
|
|
|
+track of what was required to be finished and whom was working on what.
|
|
|
Tadde\"us and Jayke were mostly working on the SVM and all kinds of tests
|
|
|
-whether the histograms were matching and alike. Fabi\"en created the functions
|
|
|
-to read and parse the given xml files with information about the license
|
|
|
-plates. Upon completion all kinds of learning and data sets could be created.
|
|
|
-Richard helped out wherever anyone needed a helping hand, and was always
|
|
|
-available when someone had to talk or ask something.
|
|
|
+whether the histograms were matching, and what parameters had to be used.
|
|
|
+Fabi\"en created the functions to read and parse the given xml files with
|
|
|
+information about the license plates. Upon completion all kinds of learning
|
|
|
+and data sets could be created. Richard helped out wherever anyone needed a
|
|
|
+helping hand, and was always available when someone had doubts about what they
|
|
|
+where doing or needed to ask something. He also wrote an image cropper that
|
|
|
+automatically exactly cuts out a character, which eventually turned out to be
|
|
|
+obsolete.
|
|
|
|
|
|
\subsubsection*{How it went}
|
|
|
|
|
|
@@ -559,4 +598,12 @@ not a big problem as no one was afraid of staying at Science Park a bit longer
|
|
|
to help out. Further communication usually went through e-mails and replies
|
|
|
were instantaneous! A crew to remember.
|
|
|
|
|
|
-\end{document}
|
|
|
+
|
|
|
+\appendix
|
|
|
+\section{Faulty Classifications}
|
|
|
+\begin{figure}[H]
|
|
|
+\center
|
|
|
+\includegraphics[scale=0.5]{faulty.png}
|
|
|
+\caption{Faulty classifications of characters}
|
|
|
+\end{figure}
|
|
|
+\end{document}
|

{kind=link}

{kind=link}
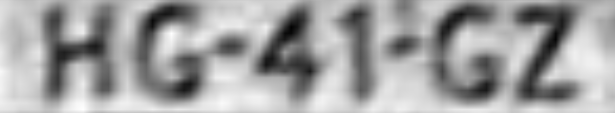
{kind=link}
{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}

{kind=link}
