|
@@ -3,6 +3,7 @@
|
|
|
\usepackage{amsmath}
|
|
\usepackage{amsmath}
|
|
|
\usepackage{hyperref}
|
|
\usepackage{hyperref}
|
|
|
\usepackage{graphicx}
|
|
\usepackage{graphicx}
|
|
|
|
|
+\usepackage{float}
|
|
|
|
|
|
|
|
\title{Using local binary patterns to read license plates in photographs}
|
|
\title{Using local binary patterns to read license plates in photographs}
|
|
|
|
|
|
|
@@ -36,7 +37,6 @@ contains photographs of license plates from various angles and distances. This
|
|
|
means that not only do we have to implement a method to read the actual
|
|
means that not only do we have to implement a method to read the actual
|
|
|
characters, but given the location of the license plate and each individual
|
|
characters, but given the location of the license plate and each individual
|
|
|
character, we must make sure we transform each character to a standard form.
|
|
character, we must make sure we transform each character to a standard form.
|
|
|
-This has to be done or else the local binary patterns will never match!
|
|
|
|
|
|
|
|
|
|
Determining what character we are looking at will be done by using Local Binary
|
|
Determining what character we are looking at will be done by using Local Binary
|
|
|
Patterns. The main goal of our research is finding out how effective LBP's are
|
|
Patterns. The main goal of our research is finding out how effective LBP's are
|
|
@@ -63,12 +63,12 @@ results made us pick Python. We felt Python would not restrict us as much in
|
|
|
assigning tasks to each member of the group. In addition, when using the
|
|
assigning tasks to each member of the group. In addition, when using the
|
|
|
correct modules to handle images, Python can be decent in speed.
|
|
correct modules to handle images, Python can be decent in speed.
|
|
|
|
|
|
|
|
-\section{Implementation}
|
|
|
|
|
|
|
+\section{Theory}
|
|
|
|
|
|
|
|
Now we know what our program has to be capable of, we can start with the
|
|
Now we know what our program has to be capable of, we can start with the
|
|
|
-implementations.
|
|
|
|
|
|
|
+defining what problems we have and how we want to solve these.
|
|
|
|
|
|
|
|
-\subsection{Extracting a letter}
|
|
|
|
|
|
|
+\subsection{Extracting a letter and resizing it}
|
|
|
|
|
|
|
|
Rewrite this section once we have implemented this properly.
|
|
Rewrite this section once we have implemented this properly.
|
|
|
%NO LONGER VALID!
|
|
%NO LONGER VALID!
|
|
@@ -94,8 +94,8 @@ Rewrite this section once we have implemented this properly.
|
|
|
\subsection{Transformation}
|
|
\subsection{Transformation}
|
|
|
|
|
|
|
|
A simple perspective transformation will be sufficient to transform and resize
|
|
A simple perspective transformation will be sufficient to transform and resize
|
|
|
-the characters to a normalized format. The corner positions of characters in the
|
|
|
|
|
-dataset are supplied together with the dataset.
|
|
|
|
|
|
|
+the characters to a normalized format. The corner positions of characters in
|
|
|
|
|
+the dataset are supplied together with the dataset.
|
|
|
|
|
|
|
|
\subsection{Reducing noise}
|
|
\subsection{Reducing noise}
|
|
|
|
|
|
|
@@ -104,7 +104,7 @@ filter. A real problem occurs in very dirty license plates, where branches and
|
|
|
dirt over a letter could radically change the local binary pattern. A question
|
|
dirt over a letter could radically change the local binary pattern. A question
|
|
|
we can ask ourselves here, is whether we want to concentrate ourselves on these
|
|
we can ask ourselves here, is whether we want to concentrate ourselves on these
|
|
|
exceptional cases. By law, license plates have to be readable. However, the
|
|
exceptional cases. By law, license plates have to be readable. However, the
|
|
|
-provided dataset showed that this does not means they always are. We will have
|
|
|
|
|
|
|
+provided dataset showed that this does not mean they always are. We will have
|
|
|
to see how the algorithm performs on these plates, however we have good hopes
|
|
to see how the algorithm performs on these plates, however we have good hopes
|
|
|
that our method will get a good score on dirty plates, as long as a big enough
|
|
that our method will get a good score on dirty plates, as long as a big enough
|
|
|
part of the license plate remains readable.
|
|
part of the license plate remains readable.
|
|
@@ -118,9 +118,9 @@ directions in the image. Since letters on a license plate consist mainly of
|
|
|
straight lines and simple curves, LBP should be suited to identify these.
|
|
straight lines and simple curves, LBP should be suited to identify these.
|
|
|
|
|
|
|
|
\subsubsection{LBP Algorithm}
|
|
\subsubsection{LBP Algorithm}
|
|
|
-The LBP algorithm that we implemented is a square variant of LBP, the same
|
|
|
|
|
-that is introduced by Ojala et al (1994). Wikipedia presents a different
|
|
|
|
|
-form where the pattern is circular.
|
|
|
|
|
|
|
+The LBP algorithm that we implemented can use a variety of neighbourhoods,
|
|
|
|
|
+including the same square pattern that is introduced by Ojala et al (1994),
|
|
|
|
|
+and a circular form as presented by Wikipedia.
|
|
|
\begin{itemize}
|
|
\begin{itemize}
|
|
|
\item Determine the size of the square where the local patterns are being
|
|
\item Determine the size of the square where the local patterns are being
|
|
|
registered. For explanation purposes let the square be 3 x 3. \\
|
|
registered. For explanation purposes let the square be 3 x 3. \\
|
|
@@ -141,8 +141,9 @@ by the n(with i=i$_{th}$ pixel evaluated, starting with $i=0$).
|
|
|
This results in a mathematical expression:
|
|
This results in a mathematical expression:
|
|
|
|
|
|
|
|
Let I($x_i, y_i$) an Image with grayscale values and $g_n$ the grayscale value
|
|
Let I($x_i, y_i$) an Image with grayscale values and $g_n$ the grayscale value
|
|
|
-of the pixel $(x_i, y_i)$. Also let $s(g_i, g_c)$ (see below) with $g_c$ = grayscale value
|
|
|
|
|
-of the center pixel and $g_i$ the grayscale value of the pixel to be evaluated.
|
|
|
|
|
|
|
+of the pixel $(x_i, y_i)$. Also let $s(g_i, g_c)$ (see below) with $g_c$ =
|
|
|
|
|
+grayscale value of the center pixel and $g_i$ the grayscale value of the pixel
|
|
|
|
|
+to be evaluated.
|
|
|
|
|
|
|
|
$$
|
|
$$
|
|
|
s(g_i, g_c) = \left\{
|
|
s(g_i, g_c) = \left\{
|
|
@@ -211,7 +212,7 @@ stored in XML files. So, the first step is to read these XML files.
|
|
|
The XML reader will return a 'license plate' object when given an XML file. The
|
|
The XML reader will return a 'license plate' object when given an XML file. The
|
|
|
licence plate holds a list of, up to six, NormalizedImage characters and from
|
|
licence plate holds a list of, up to six, NormalizedImage characters and from
|
|
|
which country the plate is from. The reader is currently assuming the XML file
|
|
which country the plate is from. The reader is currently assuming the XML file
|
|
|
-and image name are corresponding. Since this was the case for the given
|
|
|
|
|
|
|
+and image name are corresponding, since this was the case for the given
|
|
|
dataset. This can easily be adjusted if required.
|
|
dataset. This can easily be adjusted if required.
|
|
|
|
|
|
|
|
To parse the XML file, the minidom module is used. So the XML file can be
|
|
To parse the XML file, the minidom module is used. So the XML file can be
|
|
@@ -236,12 +237,12 @@ noise in the margin.
|
|
|
In the next section you can read more about the perspective transformation that
|
|
In the next section you can read more about the perspective transformation that
|
|
|
is being done. After the transformation the character can be saved: Converted
|
|
is being done. After the transformation the character can be saved: Converted
|
|
|
to grayscale, but nothing further. This was used to create a learning set. If
|
|
to grayscale, but nothing further. This was used to create a learning set. If
|
|
|
-it doesn't need to be saved as an actual image it will be converted to a
|
|
|
|
|
|
|
+it does not need to be saved as an actual image it will be converted to a
|
|
|
NormalizedImage. When these actions have been completed for each character the
|
|
NormalizedImage. When these actions have been completed for each character the
|
|
|
license plate is usable in the rest of the code.
|
|
license plate is usable in the rest of the code.
|
|
|
|
|
|
|
|
\paragraph*{Perspective transformation}
|
|
\paragraph*{Perspective transformation}
|
|
|
-Once we retrieved the cornerpoints of the character, we feed those to a
|
|
|
|
|
|
|
+Once we retrieved the corner points of the character, we feed those to a
|
|
|
module that extracts the (warped) character from the original image, and
|
|
module that extracts the (warped) character from the original image, and
|
|
|
creates a new image where the character is cut out, and is transformed to a
|
|
creates a new image where the character is cut out, and is transformed to a
|
|
|
rectangle.
|
|
rectangle.
|
|
@@ -274,29 +275,53 @@ surrounding the character.
|
|
|
\subsection{Creating Local Binary Patterns and feature vector}
|
|
\subsection{Creating Local Binary Patterns and feature vector}
|
|
|
Every pixel is a center pixel and it is also a value to evaluate but not at the
|
|
Every pixel is a center pixel and it is also a value to evaluate but not at the
|
|
|
same time. Every pixel is evaluated as shown in the explanation
|
|
same time. Every pixel is evaluated as shown in the explanation
|
|
|
-of the LBP algorithm. The 8 neighbours around that pixel are evaluated, of course
|
|
|
|
|
-this area can be bigger, but looking at the closes neighbours can give us more
|
|
|
|
|
-information about the patterns of a character than looking at neighbours
|
|
|
|
|
-further away. This form is the generic form of LBP, no interpolation is needed
|
|
|
|
|
-the pixels adressed as neighbours are indeed pixels.
|
|
|
|
|
-
|
|
|
|
|
-Take an example where the
|
|
|
|
|
-full square can be evaluated, there are cases where the neighbours are out of
|
|
|
|
|
-bounds. The first to be checked is the pixel in the left
|
|
|
|
|
|
|
+of the LBP algorithm. There are several neighbourhoods we can evaluate. We have
|
|
|
|
|
+tried the following neighbourhoods:
|
|
|
|
|
+
|
|
|
|
|
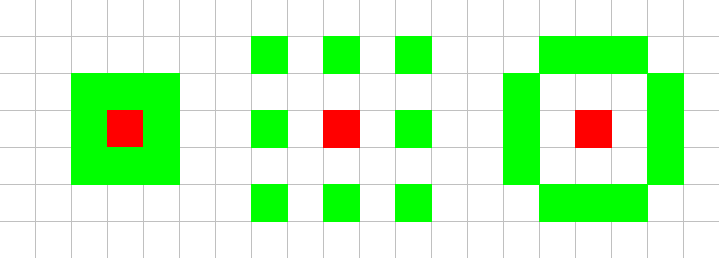
+\begin{figure}[H]
|
|
|
|
|
+\center
|
|
|
|
|
+\includegraphics[scale=0.5]{neighbourhoods.png}
|
|
|
|
|
+\caption{Tested neighbourhoods}
|
|
|
|
|
+\end{figure}
|
|
|
|
|
+
|
|
|
|
|
+We chose these neighbourhoods to prevent having to use interpolation, which
|
|
|
|
|
+would add a computational step, thus making the code execute slower. In the
|
|
|
|
|
+next section we will describe what the best neighbourhood was.
|
|
|
|
|
+
|
|
|
|
|
+Take an example where the full square can be evaluated, so none of the
|
|
|
|
|
+neighbours are out of bounds. The first to be checked is the pixel in the left
|
|
|
bottom corner in the square 3 x 3, with coordinate $(x - 1, y - 1)$ with $g_c$
|
|
bottom corner in the square 3 x 3, with coordinate $(x - 1, y - 1)$ with $g_c$
|
|
|
as center pixel that has coordinates $(x, y)$. If the grayscale value of the
|
|
as center pixel that has coordinates $(x, y)$. If the grayscale value of the
|
|
|
neighbour in the left corner is greater than the grayscale
|
|
neighbour in the left corner is greater than the grayscale
|
|
|
-value of the center pixel than return true. Bitshift the first bit with 7. The
|
|
|
|
|
-outcome is now 1000000. The second neighbour will be bitshifted with 6, and so
|
|
|
|
|
|
|
+value of the center pixel than return true. Bit-shift the first bit with 7. The
|
|
|
|
|
+outcome is now 1000000. The second neighbour will be bit-shifted with 6, and so
|
|
|
on. Until we are at 0. The result is a binary pattern of the local point just
|
|
on. Until we are at 0. The result is a binary pattern of the local point just
|
|
|
evaluated.
|
|
evaluated.
|
|
|
-Now only the edge pixels are a problem, but a simpel check if the location of
|
|
|
|
|
-the neighbour is still in the image can resolve this. We simply return false if
|
|
|
|
|
-it is.
|
|
|
|
|
|
|
+Now only the edge pixels are a problem, but a simple check if the location of
|
|
|
|
|
+the neighbour is still in the image can resolve this. We simply state that the
|
|
|
|
|
+pixel has a lower value then the center pixel if it is outside the image
|
|
|
|
|
+bounds.
|
|
|
|
|
+
|
|
|
|
|
+\paragraph*{Histogram and Feature Vector}
|
|
|
|
|
+After all the Local Binary Patterns are created for every pixel, this pattern
|
|
|
|
|
+is divided into cells. The feature vector is the vector of concatenated
|
|
|
|
|
+histograms. These histograms are created for cells. These cells are created by
|
|
|
|
|
+dividing the \textbf{pattern} in to cells and create a histogram of that. So
|
|
|
|
|
+multiple cells are related to one histogram. All the histograms are
|
|
|
|
|
+concatenated and fed to the SVM that will be discussed in the next section,
|
|
|
|
|
+Classification. We did however find out that the use of several cells was not
|
|
|
|
|
+increasing our performance, so we only have one histogram to feed to the SVM.
|
|
|
|
|
|
|
|
\subsection{Classification}
|
|
\subsection{Classification}
|
|
|
|
|
|
|
|
-
|
|
|
|
|
|
|
+For the classification, we use a standard Python Support Vector Machine,
|
|
|
|
|
+\texttt{libsvm}. This is a often used SVM, and should allow us to simply feed
|
|
|
|
|
+the data from the LBP and Feature Vector steps into the SVM and receive results.\\
|
|
|
|
|
+\\
|
|
|
|
|
+Using a SVM has two steps. First you have to train the SVM, and then you can
|
|
|
|
|
+use it to classify data. The training step takes a lot of time, so luckily
|
|
|
|
|
+\texttt{libsvm} offers us an opportunity to save a trained SVM. This means,
|
|
|
|
|
+you do not have to train the SVM every time.
|
|
|
|
|
|
|
|
\section{Finding parameters}
|
|
\section{Finding parameters}
|
|
|
|
|
|
|
@@ -309,11 +334,12 @@ available. These parameters are:\\
|
|
|
Parameter & Description\\
|
|
Parameter & Description\\
|
|
|
\hline
|
|
\hline
|
|
|
$\sigma$ & The size of the Gaussian blur.\\
|
|
$\sigma$ & The size of the Gaussian blur.\\
|
|
|
- \emph{cell size} & The size of a cell for which a histogram of LBPs will
|
|
|
|
|
- be generated.\\
|
|
|
|
|
|
|
+ \emph{cell size} & The size of a cell for which a histogram of LBP's
|
|
|
|
|
+ will be generated.\\
|
|
|
|
|
+ \emph{Neighbourhood}& The neighbourhood to use for creating the LBP.\\
|
|
|
$\gamma$ & Parameter for the Radial kernel used in the SVM.\\
|
|
$\gamma$ & Parameter for the Radial kernel used in the SVM.\\
|
|
|
$c$ & The soft margin of the SVM. Allows how much training
|
|
$c$ & The soft margin of the SVM. Allows how much training
|
|
|
- errors are accepted.
|
|
|
|
|
|
|
+ errors are accepted.\\
|
|
|
\end{tabular}\\
|
|
\end{tabular}\\
|
|
|
\\
|
|
\\
|
|
|
For each of these parameters, we will describe how we searched for a good
|
|
For each of these parameters, we will describe how we searched for a good
|
|
@@ -322,9 +348,8 @@ value, and what value we decided on.
|
|
|
\subsection{Parameter $\sigma$}
|
|
\subsection{Parameter $\sigma$}
|
|
|
|
|
|
|
|
The first parameter to decide on, is the $\sigma$ used in the Gaussian blur. To
|
|
The first parameter to decide on, is the $\sigma$ used in the Gaussian blur. To
|
|
|
-find this parameter, we tested a few values, by checking visually what value
|
|
|
|
|
-removed most noise out of the image, while keeping the edges sharp enough to
|
|
|
|
|
-work with. It turned out the best value is $\sigma = 0.5$.
|
|
|
|
|
|
|
+find this parameter, we tested a few values, by trying them and checking the
|
|
|
|
|
+results. It turned out that the best value was $\sigma = 1.1$.
|
|
|
|
|
|
|
|
\subsection{Parameter \emph{cell size}}
|
|
\subsection{Parameter \emph{cell size}}
|
|
|
|
|
|
|
@@ -339,7 +364,21 @@ the feature vectors will not have enough elements.\\
|
|
|
In order to find this parameter, we used a trial-and-error technique on a few
|
|
In order to find this parameter, we used a trial-and-error technique on a few
|
|
|
cell sizes. During this testing, we discovered that a lot better score was
|
|
cell sizes. During this testing, we discovered that a lot better score was
|
|
|
reached when we take the histogram over the entire image, so with a single
|
|
reached when we take the histogram over the entire image, so with a single
|
|
|
-cell. therefor, we decided to work without cells.
|
|
|
|
|
|
|
+cell. Therefore, we decided to work without cells.\\
|
|
|
|
|
+\\
|
|
|
|
|
+A reason we can think of why using one cell works best is that the size of a
|
|
|
|
|
+single character on a license plate in the provided dataset is very small.
|
|
|
|
|
+That means that when dividing it into cells, these cells become simply too
|
|
|
|
|
+small to have a really representative histogram. Therefore, the
|
|
|
|
|
+concatenated histograms are then a list of only very small numbers, which
|
|
|
|
|
+are not significant enough to allow for reliable classification.
|
|
|
|
|
+
|
|
|
|
|
+\subsection{Parameter \emph{Neighbourhood}}
|
|
|
|
|
+
|
|
|
|
|
+The neighbourhood to use can only be determined through testing. We did a test
|
|
|
|
|
+with each of these neighbourhoods, and we found that the best results were
|
|
|
|
|
+reached with the following neighbourhood, which we will call the
|
|
|
|
|
+()-neighbourhood.
|
|
|
|
|
|
|
|
\subsection{Parameters $\gamma$ \& $c$}
|
|
\subsection{Parameters $\gamma$ \& $c$}
|
|
|
|
|
|
|
@@ -351,7 +390,7 @@ different feature vector than expected, due to noise for example, is not taken
|
|
|
into account. If the soft margin is very small, then almost all vectors will be
|
|
into account. If the soft margin is very small, then almost all vectors will be
|
|
|
taken into account, unless they differ extreme amounts.\\
|
|
taken into account, unless they differ extreme amounts.\\
|
|
|
$\gamma$ is a variable that determines the size of the radial kernel, and as
|
|
$\gamma$ is a variable that determines the size of the radial kernel, and as
|
|
|
-such blablabla.\\
|
|
|
|
|
|
|
+such determines how steep the difference between two classes can be.\\
|
|
|
\\
|
|
\\
|
|
|
Since these parameters both influence the SVM, we need to find the best
|
|
Since these parameters both influence the SVM, we need to find the best
|
|
|
combination of values. To do this, we perform a so-called grid-search. A
|
|
combination of values. To do this, we perform a so-called grid-search. A
|
|
@@ -377,7 +416,7 @@ measure the time used to classify a license plate, not the training of the
|
|
|
dataset, since that can be done offline, and speed is not a primary necessity
|
|
dataset, since that can be done offline, and speed is not a primary necessity
|
|
|
there.\\
|
|
there.\\
|
|
|
\\
|
|
\\
|
|
|
-The speed of a classification turned out to be blablabla.
|
|
|
|
|
|
|
+The speed of a classification turned out to be ???.
|
|
|
|
|
|
|
|
\subsection{Accuracy}
|
|
\subsection{Accuracy}
|
|
|
|
|
|
|
@@ -389,15 +428,25 @@ accuracy score we possibly can.\\
|
|
|
\url{http://en.wikipedia.org/wiki/Automatic_number_plate_recognition}},
|
|
\url{http://en.wikipedia.org/wiki/Automatic_number_plate_recognition}},
|
|
|
commercial license plate recognition software score about $90\%$ to $94\%$,
|
|
commercial license plate recognition software score about $90\%$ to $94\%$,
|
|
|
under optimal conditions and with modern equipment. Our program scores an
|
|
under optimal conditions and with modern equipment. Our program scores an
|
|
|
-average of blablabla.
|
|
|
|
|
|
|
+average of ???.
|
|
|
|
|
|
|
|
-\section{Difficulties}
|
|
|
|
|
|
|
+\section{Conclusion}
|
|
|
|
|
+
|
|
|
|
|
+In the end it turns out that using Local Binary Patterns is a promising
|
|
|
|
|
+technique for License Plate Recognition. It seems to be relatively unsensitive
|
|
|
|
|
+for the amount of dirt on license plates and different fonts on these plates.\\
|
|
|
|
|
+\\
|
|
|
|
|
+The performance speedwise is ???
|
|
|
|
|
+
|
|
|
|
|
+\section{Reflection}
|
|
|
|
|
+
|
|
|
|
|
+\subsection{Difficulties}
|
|
|
|
|
|
|
|
During the implementation and testing of the program, we did encounter a
|
|
During the implementation and testing of the program, we did encounter a
|
|
|
number of difficulties. In this section we will state what these difficulties
|
|
number of difficulties. In this section we will state what these difficulties
|
|
|
were and whether we were able to find a proper solution for them.
|
|
were and whether we were able to find a proper solution for them.
|
|
|
|
|
|
|
|
-\subsection*{Dataset}
|
|
|
|
|
|
|
+\subsubsection*{Dataset}
|
|
|
|
|
|
|
|
We did experience a number of problems with the provided dataset. A number of
|
|
We did experience a number of problems with the provided dataset. A number of
|
|
|
these are problems to be expected in a real world problem, but which make
|
|
these are problems to be expected in a real world problem, but which make
|
|
@@ -415,14 +464,14 @@ are not properly classified. This is of course very problematic, both for
|
|
|
training the SVM as for checking the performance. This meant we had to check
|
|
training the SVM as for checking the performance. This meant we had to check
|
|
|
each character whether its description was correct.
|
|
each character whether its description was correct.
|
|
|
|
|
|
|
|
-\subsection*{SVM}
|
|
|
|
|
|
|
+\subsubsection*{SVM}
|
|
|
|
|
|
|
|
We also had trouble with the SVM for Python. The standard Python SVM, libsvm,
|
|
We also had trouble with the SVM for Python. The standard Python SVM, libsvm,
|
|
|
had a poor documentation. There was no explanation what so ever on which
|
|
had a poor documentation. There was no explanation what so ever on which
|
|
|
parameter had to be what. This made it a lot harder for us to see what went
|
|
parameter had to be what. This made it a lot harder for us to see what went
|
|
|
wrong in the program.
|
|
wrong in the program.
|
|
|
|
|
|
|
|
-\section{Workload distribution}
|
|
|
|
|
|
|
+\subsection{Workload distribution}
|
|
|
|
|
|
|
|
The first two weeks were team based. Basically the LBP algorithm could be
|
|
The first two weeks were team based. Basically the LBP algorithm could be
|
|
|
implemented in the first hour, while some talked and someone did the typing.
|
|
implemented in the first hour, while some talked and someone did the typing.
|
|
@@ -430,28 +479,21 @@ Some additional 'basics' where created in similar fashion. This ensured that
|
|
|
every team member was up-to-date and could start figuring out which part of the
|
|
every team member was up-to-date and could start figuring out which part of the
|
|
|
implementation was most suited to be done by one individually or in a pair.
|
|
implementation was most suited to be done by one individually or in a pair.
|
|
|
|
|
|
|
|
-\subsection{Who did what}
|
|
|
|
|
|
|
+\subsubsection*{Who did what}
|
|
|
Gijs created the basic classes we could use and helped the rest everyone by
|
|
Gijs created the basic classes we could use and helped the rest everyone by
|
|
|
keeping track of what required to be finished and whom was working on what.
|
|
keeping track of what required to be finished and whom was working on what.
|
|
|
Tadde\"us and Jayke were mostly working on the SVM and all kinds of tests
|
|
Tadde\"us and Jayke were mostly working on the SVM and all kinds of tests
|
|
|
whether the histograms were matching and alike. Fabi\"en created the functions
|
|
whether the histograms were matching and alike. Fabi\"en created the functions
|
|
|
to read and parse the given xml files with information about the license
|
|
to read and parse the given xml files with information about the license
|
|
|
plates. Upon completion all kinds of learning and data sets could be created.
|
|
plates. Upon completion all kinds of learning and data sets could be created.
|
|
|
|
|
+Richard helped out wherever anyone needed a helping hand, and was always
|
|
|
|
|
+available when someone had to talk or ask something.
|
|
|
|
|
|
|
|
-%Richard je moet even toevoegen wat je hebt gedaan :P:P
|
|
|
|
|
-%maar miss is dit hele ding wel overbodig Ik dacht dat Rein het zei tijdens
|
|
|
|
|
-%gesprek van ik wil weten hoe het ging enzo.
|
|
|
|
|
-
|
|
|
|
|
-\subsection{How it went}
|
|
|
|
|
|
|
+\subsubsection*{How it went}
|
|
|
|
|
|
|
|
Sometimes one cannot hear the alarm bell and wake up properly. This however was
|
|
Sometimes one cannot hear the alarm bell and wake up properly. This however was
|
|
|
-not a big problem as no one was affraid of staying at Science Park a bit longer
|
|
|
|
|
|
|
+not a big problem as no one was afraid of staying at Science Park a bit longer
|
|
|
to help out. Further communication usually went through e-mails and replies
|
|
to help out. Further communication usually went through e-mails and replies
|
|
|
were instantaneous! A crew to remember.
|
|
were instantaneous! A crew to remember.
|
|
|
|
|
|
|
|
-\section{Conclusion}
|
|
|
|
|
-
|
|
|
|
|
-Awesome
|
|
|
|
|
-
|
|
|
|
|
-
|
|
|
|
|
\end{document}
|
|
\end{document}
|

{kind=link}